
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- web
- 자료구조
- localdatetime
- DFS
- 정렬
- 비즈니스요구사항
- 멀티모듈
- 서버타임존설정
- 서버
- OCP
- multi module
- C++
- EC2
- 개방주소법
- 그리디
- 구현
- BFS
- 완전탐색
- DIP
- SW마에스트로
- aws
- DP
- hashcollision
- 해시충돌
- 탄력적 ip
- 객체지향설계
- STL
- google calendar api
- 에러로깅
- ZonedDateTime
Archives
- Today
- Total
레츠고✨
해시 자료구조 개념과 해시 충돌 해결 방법(자바에서 Hash Table vs Hash Map) 본문
Computer Science/Data Structure
해시 자료구조 개념과 해시 충돌 해결 방법(자바에서 Hash Table vs Hash Map)
소냐. 2024. 12. 20. 18:39
🌱 들어가기 전
해시가 정확히 뭔지, 해시 테이블과 해시 맵이 뭐가 다른지, 해시 충돌은 언제 발생하는지 제대로 아는 것이 없어서
이번 기회에 해시 자료구조에 대해서 공부하고, 해시 충돌이 발생하는 원인과 해결 방법, 언어별 해시 충돌을 어떻게 해결하고 있는지 등에 대해서 공부하고, 그 내용을 정리해보고자 한다.
✅ 해시 관련 용어 정리
해시와 관련된 다양한 용어들이 헷갈려서 먼저 각 용어를 정리해보자
Hash Function (해시 함수)
데이터를 효율적으로 관리하기 위해 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 함수
단방향 암호화 기법이다
더보기
❓단방향 암호화 기법
: 암호화는 수행하지만 복호화는 불가능한 암호화 기법
Hash (해시) = Hash Value, Hash Code
- 해시란 해시함수를 이용하여 생성된 고정된 길이의 비트열
- 해시를 만들기 위해서는 해시 함수가 필요함
- 해시 함수는 입력된 임의의 데이터(키)를 고정된 길이의 데이터(해시)로 변경하여 출력해준다
Hashing (해싱)
- Key → Hash Value 로 변환되는 과정
- 변경 전 데이터 값 : Key
- 변경 후 데이터 값 : Hash Value
해싱 : 키 -> (해시 함수) -> 해시 값(해시 코드, 해시)
이렇게 변환된 해시 코드를 배열의 인덱스로 사용하고, 해당하는 인덱스에 데이터를 저장한다.
더보기
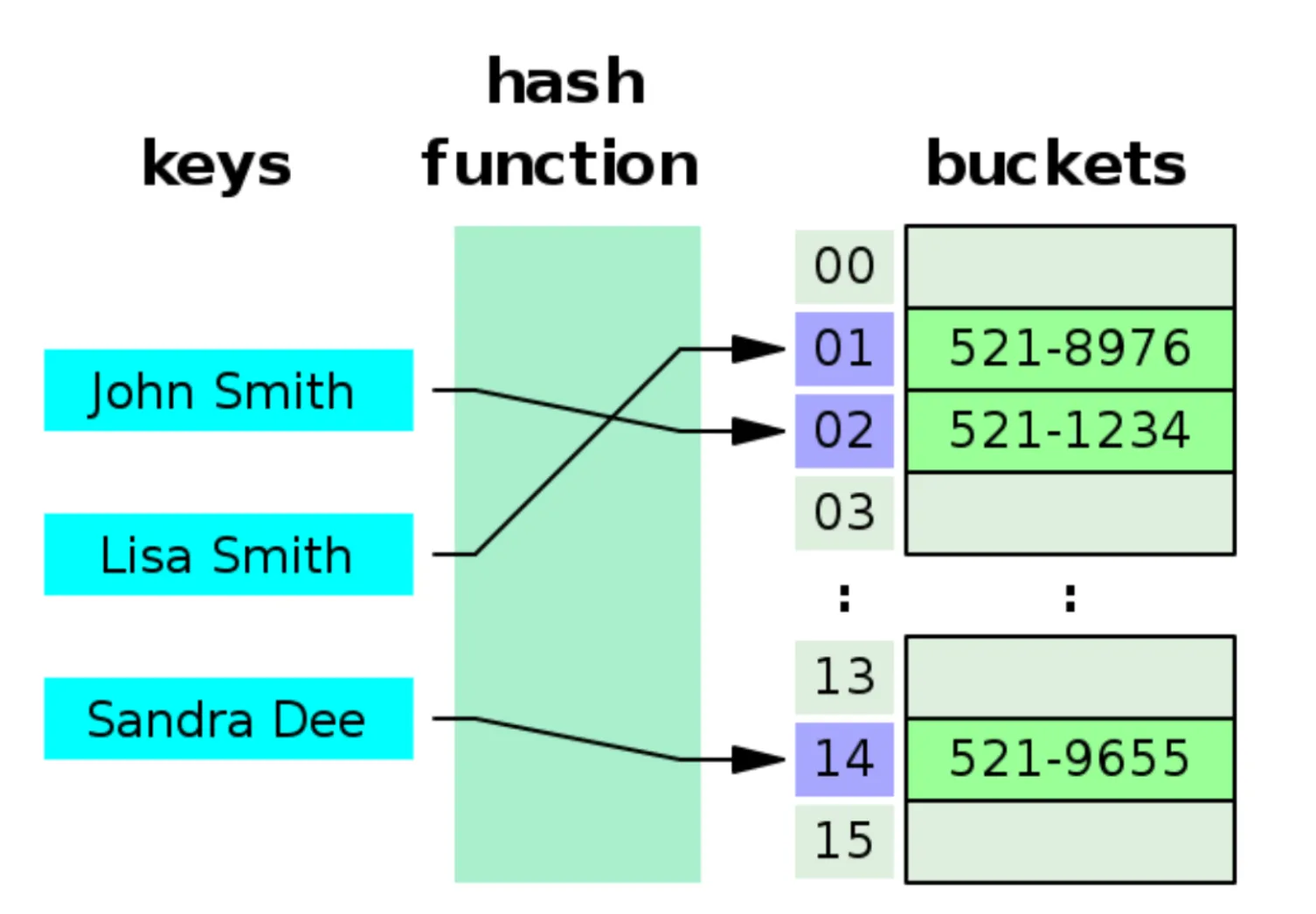
해싱 : 키 🔑 -> (해시 함수) -> 해시 값 #️⃣ (해시 코드, 해시)
이렇게 변환된 해시 코드를 배열의 인덱스로 사용하고, 해당하는 인덱스에 데이터를 저장한다.
💥 Hash Collision(해시 충돌)
- 서로 다른 문자열이 Hash Function을 통해 Hash하여 변환된 값이 중복되는 경우
- 충돌을 줄여주는 좋은 해시 함수를 사용하는 것이 좋음
- 충돌이 많아질수록 탐색의 시간복잡도가 O(1)에서 O(n)에 가까워짐

해시 충돌 해결 방법
대표적으로 체이닝(Chaining)과 개방 주소법(Open Addressing)이 있다
- 체이닝 (연결 리스트, 레드 블랙 트리 자료구조 사용)
- JDK 내부에서도 사용하고 있는 충돌 처리 방식
- data가 6개 이하 → Linked List
- data가 8개 이상 → Red-Black Tree
- data가 7일 때, 데이터 삭제하면 Linked List, 추가하면 Tree로 바꿔야 함(오버헤드 발생)
- 연결 리스트 이용 방식
- 인덱스 충돌시, 인덱스가 가리키고 있는 Linked List에 노드를 추가하여 값을 삽입
- 데이터 탐색할 때는 키에 대한 인덱스가 가리키고 있는 Linked List를 선형 탐색
- 데이터 삭제할 때는 키에 대한 인덱스가 가리키고 있는 Linked List에서 해당 노드 삭제
- 이 방식은 추가할 수 있는 데이터의 수에 대한 제약이 적다
- 시간복잡도
- 삽입, 검색, 삭제 : O(1)
- 검색, 삭제 최악의 경우 O(n) → n개의 모든 키가 동일한 해시값을 가질 때
- JDK 내부에서도 사용하고 있는 충돌 처리 방식

2. 개방 주소법
- 인덱스 충돌 처리에 대해서 Linked List와 같은 추가적인 메모리 공간 사용 X
- Hash Table Array의 빈 공간을 사용하는 방식 → 비교적 메모리 효율
- 빈 공간을 찾는 3가지 방식 : Linear Probing, Quadratic Probing, Double Hashing
- Linear Probing
- 인덱스 충돌시, 인덱스 뒤에 있는 버킷 중에 빈 버킷을 찾아서 데이터를 저장
- (ex. 152충돌 → 153에 데이터 저장)
- 데이터 탐색할 때는 Key에 대해서 검색하여 찾은 인덱스에서 Key가 일치하지 않으면 뒤의 인덱스를 검색해서 같은 키가 나오거나 키가 없을 때까지 검색을 진행
- 데이터 삭제할 때는 더미 노드를 넣어서 다음 인덱스까지 검색을 연결해주는 역할을 해줘야함(삭제가 어렵다)
- 더미 노드가 일정 개수 이상 쌓이면 해시 테이블을 리셋해줌
- Linear Probing

+ 리사이징 : 위 두 방식을 보완하는 방법
- 체이닝 : 버킷이 일정 수준으로 차 버리면 각 버킷에 연결되어 있는 Linked List의 길이가 늘어나서 검색 성능이 떨어짐 → 버킷 개수 늘려줘야 함
- 개방 주소법 : 고정 크기 배열을 사용하기 때문에 데이터를 더 넣기 위해서는 배열을 확장해야 함
- 리사이징 임계점
- 현재 데이터 개수가 해시 버킷의 75%가 될 때(0.75 = Load Factor)
- 더 큰 버킷을 가지는 Array를 새로 만든 뒤, 새로운 Array에 Hash를 다시 계산해서 복사 (보통 두 배 확장함)
✅ HashTable, HashMap
- (키 : 값)이 하나의 쌍을 이루는 데이터 구조
- 즉, 키와 배열의 인덱스를 이용하여 키를 저장하는 자료구조
- = 해시 맵, 맵, 딕셔너리, 연관 배열
- 해시함수를 사용해 키 → 해시값으로 매핑하고, 이 해시값을 색인(Index) 혹은 주소 삼아 데이터의 값(Value)을 키와 함께 저장하는 자료구조
- 이 때 데이터가 저장되는 곳을 버킷(bucket) or 슬록(slot)이라고 한다
해시 테이블의 장점
- 적은 리소스로 많은 데이터를 효율적으로 관리
- 배열의 인덱스를 사용하기 때문에 검색, 삽입, 삭제 성능이 빠름(평균 시간복잡도 : O(1))
- 키와 해시값이 연관성이 없어 보안에 많이 사용됨
- 데이터 캐싱에 많이 사용됨
- 중복 제거에 유용함
해시 테이블의 단점
- 충돌 발생할 수 있다
- 공간 복잡도가 커진다
- 순서가 있는 배열에는 어울리지 않는다
- 해시 함수 의존도가 높아진다
- 지역참조성에 취약하다
(해시 테이블 조회시 버킷들을 건너띄면서 확인하기 때문에 캐시 미스가 계속해서 발생할 수도 있다)
해시 테이블 성능
| 평균 | 최악 | |
| 탐색 | O(1) | O(N) |
| 삽입 | O(1) | O(N) |
| 삭제 | O(1) | O(N) |
✅ Java에서 HashTable vs HashMap vs ConcurrentHashMap
- Java에서는 HashTable과 HashMap 자료구조가 다르다
- 차이점 : 동기화 지원 여부(Thread-safe), Key에 Null 지원 여부
| HashTable | HashMap | ConcurrentHashMap | |
| 동기화 지원 여부 | O | O | O |
| Key에 Null 허용 여부 | X | O | X |
- HashTable
- 모든 Data 변경 메소드는 syncronized 로 선언되어 있다
- 즉, 메소드 호출 전 스레드간 동기화 락을 통해 멀티 쓰레드 환경에서 data 무결성을 보장함
- Key에 Null 값 허용하지 않는다
- HashMap의 경우
- Thread-safe 하지 않아 멀티 스레드 환경에서 동시에 객체의 data를 조작하는 data가 깨질 수 있다
- Null 값 허용함
- 하지만 HashTable 보다 ConcurrentHashMap!!
- HashTable은 Collection Framework 나오기 이전부터 존재한 구형 버전이라
- HashMap에 비해 느리다
- HashMap은 key에 null을 허용하지만 HashTable은 key에 null을 허용하지 않는다
👉 HashTable 의 get 메서드

👉 HashMap 의 get 메서드

⭐️ 결론
Java에서는 ConcurrentHashMap 써라!
✅ 언어별 해시 충돌 해결 방법 (Java, Python)
| 언어 | 해시 충돌 해결 방법 |
| C++ | 개별 체이닝 |
| Java | 개별 체이닝 |
| Go | 개별 체이닝 |
| Python | 오픈 어드레싱 |
| Ruby | 오픈 어드레싱 |
Java
- HashMap과 HashTable은 Java의 API 이름
- HashTable : JDK 1.0부터 있던 Java의 API
- HashMap : Java2에서 선보인 Java Collections Framework에 속한 API(구현체 클래스)
- HashMap vs HashTble
- HashMap과 HashTble이 제공하는 기능은 같다
- HashTable은 보조 해시 함수 사용 X
- HashMap은 보조 해시 함수 사용 O → HashTable에 비하여 해시 충돌이 덜 발생하여 성능상 이점이 있다
- 또한 HashTable 구현에는 변화가 없지만, HashMap은 지속적으로 개선되고 있다
- Seperate Chaining vs Open Addressing
- 둘 모두 Worst Case : O(n)
- 오픈 어드레싱은 연속된 공간에 데이터를 저장하기 때문에 체이닝에 비해 캐시 효율이 높다
- 데이터 개수가 적다면 오픈 어드레싱이 체이닝보다 더 성능이 좋다
- 하지만 배열의 크기가 커질수록 오픈 어드레싱의 캐시 효율 장점이 사라진다
- L1, L2 캐시 히트율이 낮아진다
- 자바 HashMap에서 해시 충돌 해결 방법 ⇒ 체이닝
- 오픈 어드레싱은 데이터를 삭제할 때 처리가 효율적이기 어렵다
- HashMap에서 remove() 메서드는 매우 빈번하게 호출될 수 있기 때문
- 게다가 HashMap에 저장된 키-값 쌍 개수가 일정 개수 이상 많아지만, 일반적으로 오픈 어드레싱은 체이닝보다 느리다.
- 오픈 어드레싱은 해시 버킷을 채운 밀도가 높아질수록 Wosrt Case 발생 빈도가 더 높아지기 때문
- 반면, 체이닝 방식은 해시 충돌이 잘 발생하지 않도록 조정할 수 있다면 최악의 경우가 발생하는 것을 줄일 수 있다 (→ 보조 해시 함수 사용)
- 자바의 로드 팩터 = 0.75
Python
- 해시 테이블로 구현된 자료형 ⇒ 딕셔너리
- 파이썬 해시 충돌 해결 방법 ⇒ 오픈 어드레싱(개방 주소법, Linear Probing)
- 파이썬은 C언어로 구현된 언어
- 체이닝 방식의 경우, malloc으로 메모리 할당하는 오버헤드가 높기 때문
💡 오픈 어드레싱 방식은 체이닝에 비해 성능이 좋다
- 하지만 슬롯이 80% 이상 차게 되면 급격하게 성능 저하가 일어나며, 체이닝과 달리 로드 팩터 1이상은 저장할 수 없다.
- 따라서 파이썬은 오픈 어드레싱 방식을 택해 성능을 높이지만 로드 팩터를 작게 잡아 성능 저하 문제를 해결한다.
- 파이썬의 로드 팩터 = 0.66

728x90
'Computer Science > Data Structure' 카테고리의 다른 글
| 🌲 B-Tree vs B+Tree 개념, 특징, 차이점, DB 인덱스에 사용되는 이유 (1) | 2024.12.20 |
|---|
'Computer Science/Data Structure' Related Articles
more
